Ich möchte bald ein paar Videos machen, für die wir ein DMBS benötigen. In diesem Video zeige ich, wie man eine einfache (unsichere und für Produktivumgebungen nicht zu verwendende!) PostgreSQL-Datenbank (17) unter FreeBSD (14.2) installieren kann.
Apple selbst sagt, dass der erste Apple Pencil mit dem aktuellen iPad Air M2 inkompatibel ist. Man könnte meinen, dass diese Aussage eher daher kommt, weil Apple vielleicht doch lieber neue Hardware verkaufen möchte, denn mit ein wenig Trickserei funktioniert dieser auch immer noch, wenn auch nicht so angenehm, wie ein neuer.
Da das aktuelle iPad keinen Lightning-Anschluss mehr hat und stattdessen auf USB-C setzt, kann der Stift nicht direkt am Gerät geladen werden. Abhilfe schaffen hier Adapter, die man für ein paar Euro kaufen kann.
Ist der Stift geladen, benötigt man noch eine Software auf dem iPad: LightBlue. Mit dieser ist es möglich, den Stift via Bluetooth zu finden und zu koppeln. Wichtig: Der Stift wurde bei mir nicht erkannt bzw. gekoppelt, wenn er eingesteckt war.
Also:
Stift ausstecken
LightBlue starten
Stift aus der Liste aussuchen
Auf „connect“ klicken (der Kopplungscode lautet 1234)
Stift funktioniert
Allerdings gibt es bei mir ein Problem: Immer, wenn ich den Stift lade, ist die Bluetooth-Verbindung „weg“. Der Stift wird, manchmal, dann noch über LightBlue angezeigt, eine Koppelung ist aber nicht möglich. Manchmal erscheint der Stift aber auch überhaupt nicht. Die Lösung, die bei mir funktioniert:
Einstellungen -> Bluetooth -> Apple Pencil entkoppeln
LightBlue starten
Stift aus der Liste aussuchen
Auf „connect“ klicken (der Kopplungscode lautet 1234)
Stift funktioniert
Das ist natürlich nervig, aber für jemanden, der den Stift nur selten nutzt, ein gangbarer Weg, ohne 100 Euro oder mehr für einen neuen Stift auszugeben.
Jeder weiß: Globale Variablen sind böse. Mir fiel jetzt auf, dass viele funktionsglobale Variablen, also Variablen, die zu Beginn einer Funktion deklariert werden, nutzen. Diese sind dann nicht im jeweiligen Scope, sondern von überall in der Funktion änderbar.
Ist dies bei Programmiersprachen wie Pascal so üblich, sollte man überlegen, ob solche Konstrukte wirklich sinnvoll sind:
#include <stdio.h>
int do_something() {
int a;
int b;
if (1 == 1) {
a = 3;
b = 4;
return a + b;
}
return 0;
}
oder man lieber im Scope bleibt (der Einfachheit wurde jetzt auf Konstanten usw. verzichtet):
#include <stdio.h>
int do_something() {
if (1 == 1) {
int a = 3;
int b = 4;
return a + b;
}
return 0;
}
Das kann natürlich zu ähnlichen Problemen und Seiteneffekten führen, wie globale Variablen. Es ist also möglich, den Wert von funktionsglobalen Variablen an jeder Stelle im Code zu überschreiben, was fehleranfällig ist und das Debugging schwieriger macht.
Go und C++ bieten mittlerweile auch Konstrukte, in denen bereits im If-Kontrollstrukturheader Variablen deklariert und definiert werden können, die für die gesamte If-Kontrollstruktur funktionieren:
if (auto x = obj.methode(); x == 3) { ... }
Ich würde dringend empfehlen, auf funktionsglobale Variablen zu verzichten.
Ein weiteres Problem innerhalb verschiedener Programmiersprachen wie C ist, dass viele dann Variablen keinen Initialwert zuordnen. Es sollte also nicht so aussehen:
int a;
sondern besser:
int a = 0;
Dies vermindert Fehler und Debugging unter Umständen erheblich.
Obwohl es bereits Redmine 6.0.1 zum jetzigen Zeitpunkt gibt, haben wir unter FreeBSD bisher leider „nur“ Version 5.1 zur Verfügung. Allerdings gab es auch eine ganze Weile lang keine lauffähige Redmine-Version für FreeBSD in den Packages und Ports.
Ich habe Version 5.1 testweise in einer VM installiert und es funktionierte problemlos. Letztlich kann man nach dieser Anleitung vorgehen:
Ich freue mich darüber, dass es funktioniert und wir Redmine weiterhin unter FreeBSD nutzen können und hoffe, dass es bald auch eine aktuellere Version gibt.
Da es in einem meiner letzten Projekte vorkam und sich jetzt auch öfter wiederholt hat, möchte ich einmal dazu etwas schreiben. Das Thema ist „Programmieren“.
Beim Programmieren in einer der meisten gängigen Programmier- oder Scriptsprachen schreibt man Quellcode. Dieser Quellcode ruft oftmals Prozeduren oder Funktionen auf, die mit den Bibliotheken beim Compiler mitkommen. Der Programmierer schreibt aber auch eigene. Dabei geht es mir um diese Themen:
Verzeichnis- und Dateihierarchie
Benamung von Dateien
Benamung von Codebestandteilen
Funktionen
Prozeduren
Klassen/Interfaces
Variablen
Konstanten
Mir ist oft aufgefallen, dass diesen Themen oftmals nur ungenügend Aufmerksamkeit geschenkt wird, dabei ist das, meiner Meinung nach, unglaublich wichtig, wenn
Der Code gewartet werden soll über Jahre oder Dekaden
Andere den Code verstehen sollen
Andere den Code ändern oder erweitern sollen
Andere den Code portieren sollen
Es keine ausreichende Dokumentation gibt
Ein Beispiel. Wir haben eine Funktion, die sieht selbst so aus und hat folgenden Inhalt:
int ab_ad_nmb_re(int pab, int p_ab, bool ab) {
int pab_list;
char *pa;
…
}
Da gibt es mehrere Probleme:
Der Funktionsname besteht aus etlichen Abkürzungen, die ein anderer nicht kennt, nachschlagen und sich merken muss. Oder immer wieder nachschlagen muss. Dementsprechend nichtssagend ist der Name
Die Variablen heißen alle fast gleich, sind nichtssagend und unglaublich verwirrend
Oftmals, von mehreren unterschiedlichen Leuten, höre ich dann folgende Argumente:
Ich weiß ja, was das alles heißt
Du kommst da schon irgendwann rein
Wir können doch keine aussagekräftigen Namen nehmen, da das dann zu lang ist und dann bringt das auch keinem was
Ehrlicherweise muss ich da sagen: Nein. Ich nehme (s. GitHub) halbwegs aussagekräftige Namen (manchmal, selten, auch mal nicht, das sollte so aber nicht sein). Sie sagen aus, was sie machen, man braucht keine oder wenig Dokumentation und auch andere sind schnell eingearbeitet und können Änderungen vornehmen.
Bezüglich langer Namen: Jeder halbwegs taugliche Editor zum Programmieren bietet Autovervollständigung. Selbst VIM bringt im Standard bereits eine kontextlose Autovervollständigung mit, die ich gerne benutze: [Strg]+[p/n]. Damit sind längere Namen kein Problem mehr, da nur der oder ein paar Anfangsbuchstaben getippt werden müssen.
Das hat viele Vorteile:
Der Code wird lesbarer
Andere können sich viel schneller einarbeiten
Der Code selbst ist Dokumentation
Mein altes Projekte Warehouse nutzt solche Namen an den meisten Stellen. Das Projekt ist von 2009 und wurde mit VIM umgesetzt. Aber schaut euch auch Frameworks an, die Methodennamen mit vernünftiger Benamung haben wie Qt, wxWidgets, Java-SDK, uvm.
Ich kann nur empfehlen, lieber den Code etwas aussagekräftiger zu gestalten, denn meiner Meinung nach zahlt sich das schnell aus. Speicher ist günstig, da machen die paar Bytes den Kohl auch nicht fett.
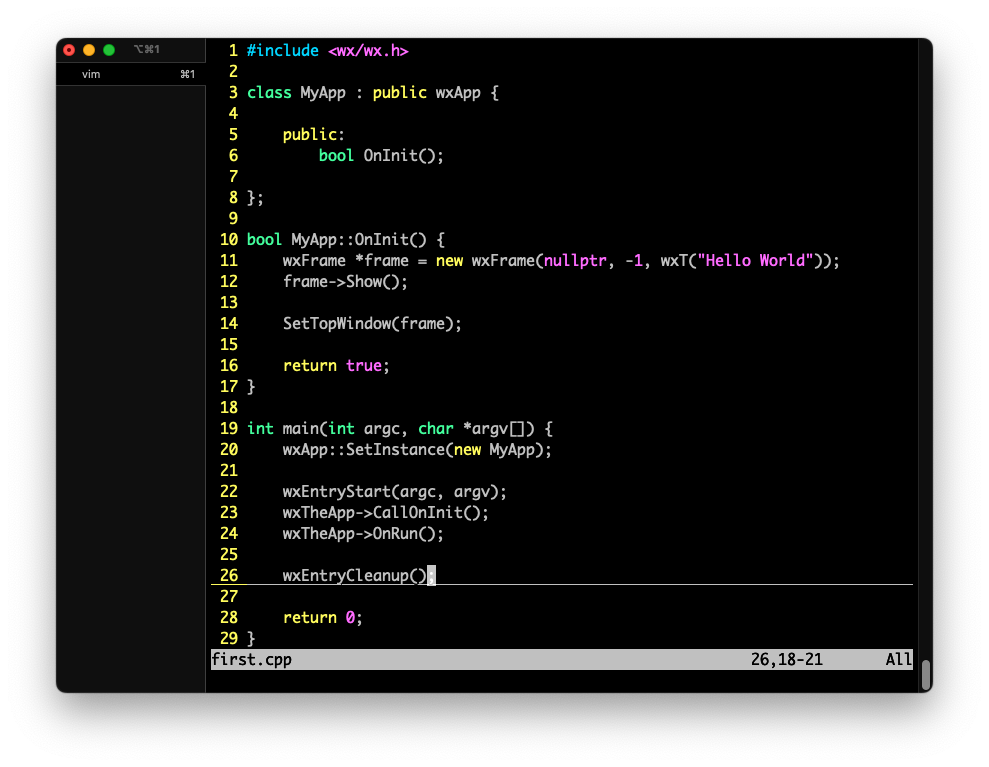
In diesem Video zeige ich das Grundgerüst einer wxWidgets-Anwendung. Wir implementieren unsere eigene wxApp und schreiben die main-Funktion einmal via wx-Makro und einmal händisch.
Viele haben mir geschrieben, dass ich doch weitere Videos bzw. Tutorials machen soll. Das freut mich sehr.
Zur Zeit nimmt mich die neue Arbeitstelle und meine Familie gut ein, ich habe aber schon die nächsten Videos geplant (Themen: wxWidgets, Qt und auch FreeBSD) und freue mich, sie bald machen und veröffentlichen zu können. Es dauert allerdings noch ein paar Tage. Aber: Es wird mit den Tutorials weiter gehen.
Wenn ihr Vorschläge für bestimmte Themen habt, gerne her damit.
Eines meiner Projekte, dass ich vor wenigen Jahren gemacht hatte, lag noch auf meiner Festplatte und war bereits lange nicht mehr aktiv. Ich dachte mir allerdings, dass ich das noch einmal gerne als Referenz von mir online stellen wollte: compow.
Bei compow handelt es sich um eine Website, auf der sich Firmen vorstellen können und Stellenanzeigen schalten können. Ursprünglich war das mal kostenpflichtig, was ich aber herausgenommen habe, da ich nicht selbständig bin und damit kein Geld verdiene, es ist lediglich eine meiner Referenzen.
Das Interessante an der Website ist der Tech-Stack, denn anstelle einer der üblichen Webprogrammiersprachen wie Ruby, PHP, Python, Go, ASP.NET (keine Sprache, aber ihr wisst, was ich meine), basiert diese Website auf folgenden Technologien:
Wie gesagt, die Seite dient einfach nur als Referenz, womit ich mich in den letzten Jahren beschäftigte. Die Website ist nicht weiterentwickelt und wird es mitunter auch nicht.
Disclaimer: Ich schreibe hier privat meine Meinung. Ich behaupte nicht, dass irgendeine App unsicher ist, Datenhandel betreibt, unseriös ist usw. Dies ist meine private Meinung.
Es muss vor ungefähr zwei Jahren gewesen sein (vielleicht länger, vielleicht kürzer), als unser damaliger Kindergarten die Kita-Info-App einführte. Ich sah mir die Software an und war direkt davon überzeugt: Nein, das sieht nicht gut aus (Sicherheit, Datenerhebung, Qualität, usw.): wir machen da nicht mit. Meine Frau war gleicher Meinung. Wir hatten dann ein Gespräch mit der Kita-Leitung und erläuterten unsere Bedenken. Wir wurden an die nächste höhere Stelle verwiesen, die unsere Bedenken für grundlos hielt. Naja: https://www.heise.de/news/Datenleck-bei-beliebter-KiTa-App-Stay-Informed-9662578.html
Wir waren umgezogen, neuer Kindergarten, keine App, also alles super. Dann wurde vor ein paar Wochen mit clivver eine neue Kita-App eingeführt und wieder schaute ich mir die an. Ich wurde hellhörig, als ich sah, welche Informationen die App für die Nutzung vom Hersteller haben möchte (Stand 26.03.2024):
Vorname
Nachname
Mobilfunknummer
Device-ID: Android ID / Identifier for Vendor
Zeitpunkt der Registrierung
Vorname des Kindes
Meldungen zu einem Kind / sich selbst
Zeitpunkt des Öffnens einer Nachricht
Da wurde mir bereits schlecht und es stimmt nicht, denn die App benötigt noch eine weitere Information, die anscheinend bereits erhoben und auf den Servern gespeichert wurde: Das Geburtsdatum des Kindes.
Bis auf „Zeitpunkt der Registrierung“ (aus statistischen Gründen oder zur späteren Löschung bei Inaktivität) kann ich alle weiteren erhobenen Daten der Eltern und des Kindes nicht nachvollziehen. Über die App werden verschiedene Informationen ausgetauscht:
Nachrichten an alle/Gruppen
an Personal
Umfragen
Kalendereinträge
Krankmeldungen
Zuhause-Info (mein Kind bleibt heute zu Hause)
Mittagsessen-Info (mein Kind isst mit und was es isst)
Kommentare
Weiterhin hörte ich, ob es stimmt, weiß ich nicht, dass bsplw. Bilder, die Kinder gemalt haben oder Bilder von Gebasteltem darin verschickt werden.
Als Techniker im Allgemeinen und letztlich auch sowas wie „Digital Native“ im Engeren finde ich eine solche App erstmal super. Aber nur, wenn sie vernünftig gemacht ist.
Was ich damit meine: Warum werden diese Daten erhoben und warum ist nicht alles anonymisiert? Welchen Zweck hat für den Austausch mein Name, das Geburtsdatum meines Kindes, meine Device-ID, usw.?
Ich wollte es mir nicht nehmen lassen und schrieb an den Entwickler der App, seines Zeichens ehemaliger Journalist, ein paar Fragen:
Sehr geehrte Damen und Herren,
unsere Kita setzt ab jetzt clivver ein. Bevor ich den seitenlangen „Datenschutzbestimmungen“ zustimme, habe ich doch ein paar Fragen:
Wo werden die personenbezogenen Daten gespeichert?
Wie sind die personenbezogenen Daten verschlüsselt?
Wer hat Zugriff auf die personenbezogenen Daten?
Wozu wird die Telefonnummer gebraucht?
Wozu wird das Geburtsdatum des Kindes benötigt?
Ist die Kommunikation Ende-zu-Ende verschlüsselt?
Wie werden Backups angelegt, sind diese verschlüsselt und wer hat Zugriff?
Werden nach dem Löschen des Accounts auch alle Daten aus dem Backupbestand restlos entfernt?
Welche Daten werden in der Cloud (Firebase) gespeichert, wo liegen diese Daten und wer hat Zugriff darauf und werden die Daten seitens Google weiterverwendet?
Die erstellende und betreibende Firma sieht nach einer Privatperson aus, die im journalistischen Umfeld tätig ist (Sascha Müller-Jänsch). Gibt es im Unternehmen eine technische Abteilung, die die Expertise hat, eine solche Software sicherheitstechnisch zu betreiben?
Warum werden die Daten nicht vollständig anonymisiert? Weder die Eltern noch die Kinder erhalten eine Rechnung, damit werden die Daten letztendlich nicht benötigt. Mich interessiert, warum diese dann erhoben werden, da ja die Kita die Rechnungen be- gleicht.
Wir haben Zettel erhalten, auf denen unsere Namen sowie der Name unseres Kindes vermerkt sind und es findet ein Matching in der App für das Geburtsdatum des Kindes statt. Wo sind meine persönlichen Daten und die meines Kindes jetzt bereits (vor Registrierung) ge- speichert und wer hat mein Einverständnis zu dieser Speicherung gegeben?
Vielen Dank für die Beantwortung der Fragen und mit freundlichen Grüßen
Thorsten Geppert
E-Mail vom 28.02.2024
Ich bekam auch eine, für mich sehr schwammige, Antwort. Ich fragte nach, ob ich aus dieser Antwort zitieren dürfte. Das wurde abgelehnt. Wie die Antwort aussah, möchte ich aus einem Gedankenprotokoll anhand eines Beispiels klar machen:
Die Frage: „Wie sind die personenbezogenen Daten verschlüsselt?“ – Die Antwort: „Ja, sie sind verschlüsselt.“
Da ich nicht aus der Antwort zitieren darf, möchte ich da auch nicht weiter drauf eingehen und respektiere den Wunsch (und kann ihn an der Stelle auch absolut nachvollziehen…).
Verstehen konnte ich auch nicht die Antwort der nächst höheren Stelle der Kita, die von einem Mitglied des Eltenrbeirats angeschrieben wurde. Ich habe gefragt, ob ich diese E-Mail zitieren darf. Die Antwort kam spät, war aber ein Nein. Ich möchte das aber dennoch ohne O-Ton zusammenfassen, zumindest zwei Punkte:
Wenn der Hersteller zusichert, dass die Software DSGVO-konform betrieben wird, dann ist das so
Wir müssen mit Sicherheitslücken und auch damit, dass wir Opfer werden können, leben, wichtig sei nur, dass diese Mängel schnell beseitigt werden
Also interpretiere ich das so: Wenn Ihre Daten und die sensiblen Daten Ihres Kindes geleakt werden, dann ist das ok, da sie ja DSGVO-konform geleakt sind und der Mangel sicher bald schnell beseitigt wird…
Allerdings wurde noch mitgeteilt, dass wenn wir Datenschutzverletzungen feststellen, wir diese melden können und sie denen nachgehen würden.
In der E-Mail-Antwort der höheren Stelle wurde mir aber mitgeteilt, ich würde seine/ihre Worte nicht richtig interpretieren. Eine Relativierung der Problematiken wäre es damit nicht, sondern im Gegenteil. Dann kam direkt der Satz, dass ich aber die E-Mail nicht zitieren darf, um weitere Missverständnisse zu vermeiden.
Bevor ich noch auf ein wenig Technik komme, mal einen Gedankenanreiz für die, die meinen, dass es sich hier nicht um sensible Daten „Schutzbefohlener“ handelt. Bei einem Datenleak könnten die Daten von Ihnen und Ihrem Kind veröffentlicht werden:
Der jenige kennt den Namen von Ihnen und Ihrem Kind
Er kennt auch Ihre eindeutige Telefonnummer
Er weiß, wann Ihr Kind krank war und wie häufig, kann mitunter Rückschlüsse auf chronische Probleme ziehen
Er weiß, wann Ihr Kind in den Kindergarten geht
Er weiß vielleicht, wenn das mit den oben erwähnte Bildern stimmt, mitunter welchen kognitiven Zustand ihr hat, vor allem in Kombination mit dem Geburtsdatum (Es malt weiter unter der Alterserwartung… usw.)
Er kann Rückschlüsse auf Nahrungsunverträglichkeiten ziehen
Es lässt sich ein detailiertes Profil Ihres Kindes und teils Ihrer Familiensituation feststellen (Kind wird mittags geholt, sprich, Sie oder Ihr Partner arbeiten nur halbtags…).
Das wäre meiner Meinung nicht nötig, wenn man diese Daten nicht erhebt, bsplw. wenn das Kind nur eine Nummer ist und keine persönlichen Daten dazu getauscht werden und die Zuordnung zum Kind ausschließlich in der KITA erfolgt. Dann wäre ein Datenleak nicht ganz so schlimm. Das ist hier aber nicht der Fall.
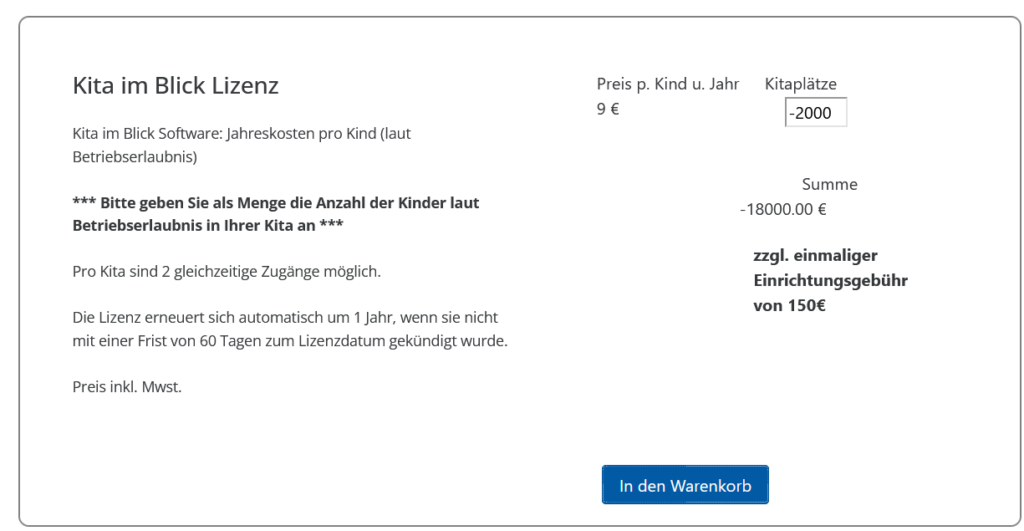
Kommen wir zu etwas technischem, aber ich gehe da nicht in die Tiefe, da mir hier die Zeit zu fehlt. Wenn man sich die Website des Entwicklers ansieht, dann sieht man, dass dieser das Portal „Kita im Blick“ betreibt. Wenn man dort eine Bestellung aufgeben will, kann man sowas machen:
Das wird auch so in den Warenkorb übernommen:
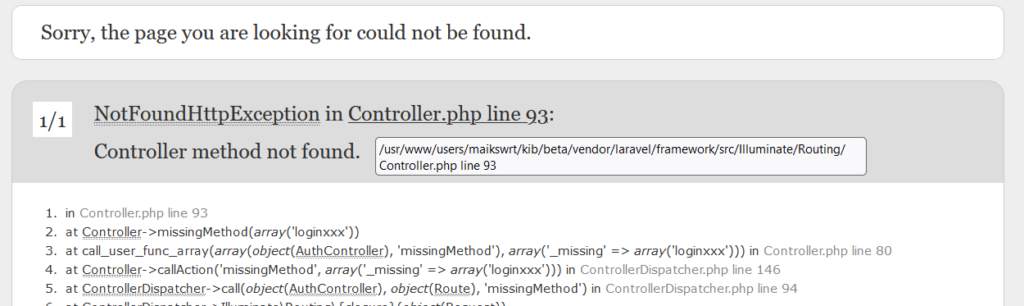
Schaut man sich dann noch diese (von mir manipulierte) URL an: https://www.kitaimblick.com/kib/beta/public/auth/loginxxx stellt man zwei Dinge fest:
In der URL erscheint das Wort „beta“, was auch immer das (rechtlich) bedeuten mag
Es erscheint eine Fehlermeldung, in der sogar absolute Dateipfade sichtbar sind
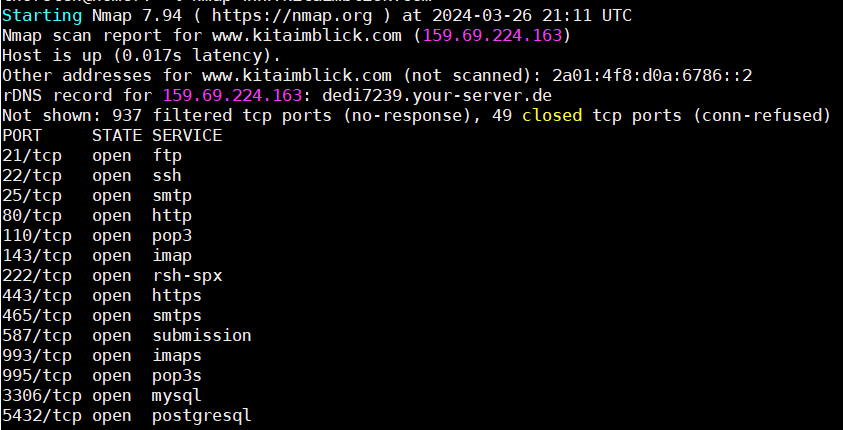
Wenn wir uns dann noch ein nmap auf diesem Server ansehen, bekommen wir:
Dass bsplw. PostgreSQL und MySQL nach außen offen sind, muss nichts bedeuten, gibt aber ein ungutes Gefühl. Wir wissen nicht, ob dort Ihre Daten liegen und wie weit die gesichert sind.
Das war nur an der Oberfläche gekratzt und meine Frau und ich haben entschieden: wir machen bei clivver nicht mit, unsere Entscheidung. Mir fehlt leider die Zeit, da tiefer zu gehen.
Was ich aber gerne raten möchte ist: Hinterfragen Sie immer, warum gewisse Daten erhoben werden. Überlegen Sie, ob sie notwendig sind und wenn Sie auch nur ein minimales ungutes Gefühl haben, lassen Sie es lieber.
Noch einmal: ich rate auf keinen Fall von solchen Apps ab, ich sage nicht, dass sie unsicher sind, Datenlücken haben oder Datenhandel damit betrieben wird.