Eigentlich möchte ich hier in diesem Blog nicht politisch werden. Dennoch habe ich das Gefühl, dass wir uns als Gesellschaft massiv rückentwickeln und Dinge, für die viele Menschen Jahre oder Jahrzehnte gekämpft haben, weil sie sinnvoll und wichtig sind, mit einem Fingerschnipp entfernen.
Das Geniale, wie ich finde, an der Sache ist: Man nimmt nicht zunächst starken, wehrhaften Menschen Dinge weg. Das würde sicher zu großen Aufschreien, Problemen und Juristereien führen. Man nimmt es denen weg, die (hoch-) vulnerabel sind und sich mitunter nicht wehren können. Da erwartet man keinen oder nur wenig Widerstand, sind es doch kleine, nicht wehrhafte Grüppchen ohne Lobby. Rentner. Behinderte. Alleinerziehende. Arme. Gebrechliche. Kranke. Das Interessante daran ist, dass jeder, außnahmslos jeder, eines Tages einer oder mehrerer dieser Gruppen angehören kann. Du wirst alt, bist nicht reich, du wirst Renter. Du hast einen Unfall oder einen Schlaganfall, du wirst zum Behinderten. Du hast einen Partner und ein Kind, der Partner stirbt, du bist alleinerziehend. Du verlierst deinen Job und findest aufgrund deines Alters keinen neuen, du wirst arm. Du wirst alt, du wirst gebrechlich. Der Krebs wuchert in deinem Körper, du wirst krank.
Verschiedene Kinder brauchen in der Schule Hilfe in Form einer Begleitperson, der sogenannten Schulbegleitung, zur Teilhabe am Unterricht, aber auch am sozialen Miteinander in der Schule. Die Schulbegleitung übernimmt mehrere Aufgaben. Sie vermittelt zwischen Kind und Kindern, zwischen Kind und Lehrern, sie hilft, Aufgaben zu verstehen, formuliert um, übernimmt manchmal das Schreiben, übersetzt soziale Ereignisse, die das Kind nicht versteht und macht noch vieles mehr. Ohne jemanden, der sich in dem Bereich nicht auskennt, ist kaum oder keine Teilhabe möglich. Das führt natürlich zu verschiedenen anderen Problemen. Das Kind kann mitunter nicht zur Schule, die Schule bedroht die Eltern mit Zwangsmaßnahmen, das Jugendamt wird eingeschaltet, es könnte Kindeswohlgefährdung geben, das Kind verpasst viel Schulstoff … es gibt noch so viel mehr.
Laut dem Autismus Hamburg e.V. soll es in Hamburg eine massive Kürzung der Schulbegleitung geben. Sie haben dazu einen offenen Brief verfasst. In diesem steht genau drin, warum diese Idee schlecht ist und was sie fordern. Lest euch das einmal durch. Es ist schlimm und wenn das Modell gefahren wird, kann es als nächstes dann die nächsten Kinder (und bald arbeitslosen Schulbegleiter) treffen.
Das Bild ist folgendes: Mr. Burns nimmt Baby den Lutscher weg.
Ich habe in einem Blogartikel zusammengefasst, worauf im Speziellen Schulleiter bei neurodivergenten Kindern achten sollten. Vielleicht ist der Artikel auch für andere interessant, denn es geht generell um Neurodiversität im Schulalltag. Hier geht es zum Artikel.
Jeder, der anfängt zu programmieren, stellt dieselbe Frage: Welche Sprache soll ich lernen? Und jedes Mal bekommt man unterschiedliche Antworten — weil die Antwort davon abhängt, was man bauen will, woher man kommt und wie viel Frustration man bereit ist zu ertragen.
Ich mache es einfach. Hier ist meine Einschätzung, basierend auf zwanzig Jahren Erfahrung damit, Code zu schreiben und zu erklären. Keine akademische Rangliste. Sondern: Was ist nützlich? Was ist zugänglich? Und wo verbringt man mehr Zeit mit Kämpfen gegen die Sprache als mit dem eigentlichen Problem?
Python — Der empfohlene Einstieg
Python ist die Sprache, die ich jedem nenne, der fragt. Nicht weil sie die beste ist — sondern weil sie am wenigsten im Weg steht.
Die Syntax ist minimal: Keine Klammern, keine Semikolons, Einrückung ist Struktur. Man liest Python-Code wie englische Anweisungen. Das klingt banal, ist aber der wichtigste Faktor für Anfänger: Wenn man den Code lesen kann, kann man ihn verstehen. Wenn man ihn versteht, kann man ihn verändern. Und verändern ist wie Programmieren.
print("Hallo, Welt!")
Das ist ein vollständiges Python-Programm. Eine Zeile. Keine Importe, keine Klassendefinition, keine main-Funktion. Man speichert es als hallo.py und führt es aus mit python hallo.py. Fertig.
Nützlich ist Python für fast alles: Skripte, Automatisierung, Web-Backend (Django, Flask), Datenanalyse (Pandas, NumPy), Machine Learning (PyTorch, scikit-learn), Systemadministration. Die Standardbibliothek ist absurd umfangreich — man bekommt oft ohne ein einziges pip install erstaunlich viel erledigt.
Der Nachteil: Python ist langsam. Nicht „ein bisschen langsamer“ — richtig langsam, oft 10-100x gegenüber kompilierten Sprachen. Aber für den Einstieg ist das irrelevant. Wenn man an den Punkt kommt, wo Geschwindigkeit zählt, hat man schon längst verstanden, wie man programmiert.
Lernkurve: Flach. Die ersten Ergebnisse kommen in Minuten. Komplexere Konzepte (OOP, Generatoren, Dekoratoren) brauchen Zeit, aber man kommt sehr weit ohne sie.
JavaScript — Weil der Browser überall ist
JavaScript ist die einzige Sprache, die auf jedem Rechner der Welt läuft, ohne dass man etwas installieren muss. Jeder Browser ist eine JavaScript-Laufzeitumgebung. Das macht sie zur einzigen Sprache, bei der man sein Ergebnis sofort teilen kann — einfach eine HTML-Datei, aufgemacht im Browser, fertig.
Speichern als .html, Doppelklick, Ergebnis. Kein Server, kein Build-Schritt, kein nichts.
JavaScript hat zwei Gesichter: Im Browser ist es die DOM-Manipulation, Event-Handling, UI-Logik. Auf dem Server (Node.js) ist es ein vollwertiges Backend mit Zugriff auf Dateisystem, Netzwerk, Datenbanken. Dasselbe Sprache, zwei Welten.
Das Problem mit JavaScript: Die Sprache hat viele historische Macken. == vs. ===, das Verhalten von this, var vs. let vs. const, die ganze Asynchronität mit Callbacks, Promises, async/await — das ist eine Menge, die man nicht sofort verstehen muss, die aber irgendwann auf einen wartet. Und das Ökosystem ist berüchtigt für seine Abhängigkeitshölle: Ein npm install zieht hundert Pakete, und man versteht kein einziges.
Trotzdem: Wenn man Dinge bauen will, die im Browser laufen, gibt es keine Alternative. Und der Browser ist der Ort, wo Menschen Software erleben.
Lernkurve: Mittel. Der Einstieg ist einfach (öffne die Konsole, tippe console.log), aber die Tiefe ist tückisch. Man kommt schnell zu Ergebnissen, aber man schreibt lange Zeit Code, den man nicht vollständig versteht.
Rust — Für die, die es richtig lernen wollen
Rust ist die schwerste Sprache in dieser Liste und diejenige, die ich am spätesten nenne. Aber ich nenne sie, weil sie etwas lehrt, das andere Sprachen vernachlässigen: Wie Speicher funktioniert.
fn main() {
println!("Hallo, Welt!");
}
Sieht einfach aus. Ist es aber nicht. Das ! hinter println verrät es schon: Das ist ein Makro, keine Funktion. Rust hat Makros, Traits, Lifetimes, Ownership, Borrowing — Konzepte, die man in Python oder JavaScript nie sieht, weil die Laufzeitumgebung sie versteckt.
Warum sollte man das als Anfänger lernen wollen? Weil man versteht, was unter der Abstraktion passiert. Wenn man in Python eine Liste an eine Funktion übergibt, fragt man sich nicht, ob das eine Kopie oder eine Referenz ist. In Rust muss man das wissen. Das ist anstrengend. Aber es macht einen zu einem besseren Programmierer in jeder anderen Sprache.
Rust ist die Sprache, die den Compiler als Lehrer nutzt. Der Compiler lehnt Code ab, der Speicherprobleme haben könnte. Die Fehlermeldungen sind legendarisch gut — sie erklären nicht nur, was falsch ist, sondern auch, wie man es fixt. Man kämpft gegen den Compiler. Und dabei lernt man.
Praktisch ist Rust für Systemnahe Programmierung: Betriebssystem-Komponenten, Treiber, CLIs, WebAssembly, Netzwerk-Dienste, die Performance brauchen. Firefox‘ Rendering-Engine Servo ist in Rust. Teile von Windows, Linux und FreeBSD sind in Rust. Die Sprache hat Momentum.
Lernkurve: Steil. Die ersten Wochen sind frustrierend, weil der Compiler fast alles ablehnt. Aber wenn es klickt, klickt es richtig.
Go — Einfach, aber nicht primitiv
Go (Golang) ist die Sprache, die Google gemacht hat, weil C++ zu komplex und Python zu langsam war. Das Design ist radikal minimalistisch: Keine Vererbung, keine Generics (bis vor kurzem), keine Exceptions, keine drei Wege, dasselbe zu tun.
package main
import "fmt"
func main() {
fmt.Println("Hallo, Welt!")
}
Mehr Boilerplate als Python — aber immer noch überschaubar. Das package main, das import, die func main() — das ist ein festes Gerüst, das man einmal lernt und dann immer wieder verwendet.
Go glänzt dort, wo man Concurrent-Programmierung braucht: Webserver, APIs, Microservices, Kommandozeilen-Tools. Goroutinen und Channels sind das eleganteste Concurrency-Modell, das ich in einer imperativen Sprache gesehen habe. Statt Threads und Locks schreibt man:
go func() {
ch <- result
}()
Und das war’s. Kein Thread-Pool, kein Mutex, kein Deadlock-Risiko.
Was Go für Anfänger attraktiv macht: Die Sprache ist klein. Die Spezifikation hat weniger als 100 Seiten. Man kann die gesamte Sprache in einem Wochenende lesen und verstehen. Das bedeutet, dass man schnell produktiv ist — und dass es keine überraschenden Ecken gibt, die man noch nicht kennt.
Der Nachteil: Go ist pragmatisch, nicht elegant. Fehlerbehandlung ist if err != nil auf jeder zweiten Zeile. Keine Sum Types, keine Pattern Matching, keine Algebriaischen Datentypen. Wer aus der funktionalen Welt kommt, wird frustriert sein. Wer aus der Systemwelt kommt, wird begeistert sein.
Lernkurve: Flach bis mittel. Die Sprache ist schnell gelernt. Das Concurrency-Modell braucht mehr Zeit, um es richtig zu verstehen.
C — Weil man verstehen sollte, worauf alles läuft
C ist die Sprache, die man lernen sollte, wenn man verstehen will, wie Computer wirklich funktionieren. Nicht als erste Sprache — aber als zweite oder dritte.
#include <stdio.h>
int main(void) {
printf("Hallo, Welt!\n");
return 0;
}
Kompilieren mit gcc -o hallo hallo.c, ausführen mit ./hallo. Das ist mehr Aufwand als Python. Aber man sieht: Hier gibt es kein Automatisches Speichermanagement. Es gibt Pointer. Es gibt manuelle Speicherallokation mit malloc und free. Es gibt Buffer Overflows. Es gibt Segmentation Faults.
Und genau deshalb sollte man C lernen: Um zu verstehen, was unter den Abstraktionen passiert, die Python, JavaScript und Go bieten. Wenn man einmal einen Segfault debuggt hat, versteht man, warum Rusts Ownership-Modell existiert. Wenn man einmal malloc und free manuell verwaltet hat, versteht man, warum Garbage Collection nützlich ist.
Praktisch: C ist überall. Betriebssysteme (FreeBSD, Linux, Windows), eingebettete Systeme, Treiber, Datenbanken, Netzwerk-Stacks. Wenn man tief genug graben will, kommt man an C nicht vorbei.
Lernkurve: Mittel, aber mit Fallgruben. Die Syntax ist simpel. Die Semantik ist tief. Pointer und Speichermanagement sind die härteste Hürde für Anfänger.
Was ich nicht empfehle (und warum)
Java — Nicht weil Java schlecht ist, sondern weil der Einstiegs-Overhead frustrierend ist. Klassendefinition, public static void main(String[] args), javac, java — für ein Hello World braucht man mehr Boilerplate als in jeder anderen Sprache hier. Java lehrt OOP, aber OOP ist nicht das erste, was ein Anfänger braucht.
C++ — C++ ist mächtig, aber die Komplexität ist für Anfänger grausam. Die Sprache hat zu viele Wege, Dinge zu tun. Smart Pointers, Move Semantics, Templates, RAII — alles wichtig, alles überwältigend. Wer C++ lernen will, sollte zuerst C können.
PHP — PHP hat sich mit Version 8 deutlich verbessert. Aber das Ökosystem und die Kultur sind immer noch geprägt von einer Zeit, in der Sicherheit und Code-Qualität nachrangig waren. Als Einstiegssprache würde ich es heute nicht mehr empfehlen.
Die Reihenfolge, die ich vorschlage
Python — Lernen, wie man denkt. Wie man Probleme in Schritte zerlegt. Wie man Code liest und schreibt.
JavaScript — Lernen, wie man Dinge baut, die Menschen sehen und benutzen.
C — Lernen, was unter der Haube passiert.
Rust oder Go — Je nachdem, ob man Sicherheit (Rust) oder Einfachheit (Go) priorisiert.
Die wichtigste Erkenntnis: Die erste Sprache ist nicht die letzte. Man wird mehrere lernen. Die Frage ist nicht, welche Sprache man wählt, sondern ob man anfängt.
Und dafür gilt: Je weniger im Weg steht, desto besser. Deshalb Python.
Hello-World-Vergleich
Sprache
Zeilen
Kompilieren?
Typsystem
Python
1
Nein
Dynamisch
JavaScript
1
Nein
Dynamisch
Go
5
Ja
Statisch
Rust
3
Ja
Statisch
C
5
Ja
Statisch
Weniger Zeilen bedeuten nicht zwingend eine einfachere Sprache. Aber für den Einstieg zählt: Wie schnell komme ich vom Öffnen des Editors zum ersten laufenden Programm? Und da gewinnt Python.
Die BSD‑Familie hat ihre Wurzeln in der Berkeley Software Distribution (BSD), die 1977 von der University of California, Berkeley, als Weiterentwicklung des frühen UNIX‑Systems veröffentlicht wurde. Die ersten öffentlichen BSD‑Versionen (1.0 – 4.3) legten das Fundament für den heute bekannten TCP/IP‑Protokoll‑Stack, der damals noch ein Forschungsexperiment war, heute aber das Rückgrat des Internets bildet.
Im Laufe der 1990er‑Jahre spaltete sich das Projekt in mehrere unabhängige Richtungen:
FreeBSD (gegründet 1993) fokussierte sich schnell auf Performance, Stabilität und eine umfangreiche Ports‑Sammlung für Drittsoftware.
OpenBSD (ab 1995) verfolgte das Ziel, ein so sicher wie möglich zu sein. Der Name selbst stammt von der Kombination aus „Open“ und „BSD“ und betont Transparenz.
NetBSD (1993) wählte den Pfad der Portabilität – das berühmte Motto „runs on anything“ stammt von NetBSD und spiegelt die Unterstützung von über 50 Prozessorarchitekturen wider.
DragonFlyBSD (2003) entstand aus einem Fork von FreeBSD 4.8, weil einige Entwickler mit der Entwicklungsgeschwindigkeit und den SMP‑Architekturen unzufrieden waren. Das Ergebnis: ein System, das stark auf Multi‑Core‑Skalierung und ein eigenes Dateisystem HAMMER2 setzt.
Diese unterschiedlichen Wurzeln bestimmen bis heute die Design‑Entscheidungen, das Community‑Verhalten und die Einsatzbereiche der einzelnen Betriebssysteme.
Philosophie, Entwicklungsmodell und Lizenzierung
Projekt
Zielsetzung
Entwicklungsmodell
Lizenzierung
FreeBSD
Hoch‑performante Server‑ und Desktop‑Plattform
Zentralisiertes Kernteam, Commit‑Access über Core‑Team; offene Ports‑Tree-Pflege durch freiwillige Maintainer
BSD‑Lizenz (2‑Clause) + CDDL für ZFS (Kompatibilitäts‑Ausnahme)
OpenBSD
Sicherheit über alles, Code‑Qualität, Audits
Kleine, sehr konservative Entwicklergemeinschaft; Ein‑Person‑Commit‑Policy; jede Änderung wird auditiert
BSD‑Lizenz (ähnlich der 2‑Clause); kein CDDL, alles rein Open‑Source
NetBSD
Portabilität, Sauberkeit des Codes, Unterstützung exotischer HW
Dezentralisiert, Git‑basiertes Repository; pkgsrc (Quellpaket‑System) wird separat gepflegt
BSD‑Lizenz (2‑Clause) – keine zusätzlichen Einschränkungen
Die Lizenzierung ist ein wichtiger Faktor für Unternehmen. FreeBSD enthält den CDDL‑Teil für ZFS, was in manchen Unternehmens‑Compliance‑Szenarien zu Diskussionen führt. OpenBSD, NetBSD und DragonFlyBSD verwenden ausschließlich die klassische BSD‑Lizenz, was ihre Nutzung in proprietären Projekten vereinfacht.
Typische Einsatzszenarien – Wo welches BSD am besten passt
Web‑ und Datenbank‑Server
FreeBSD ist dank ZFS‑Integration, Jails und einer ausgereiften TCP‑Stack‑Optimierung (z. B. TCP‑Fast‑Open, RACK‑Algorithmus) die erste Wahl für große Web‑Farmen. Unternehmen wie Netflix, Yahoo! und GitHub betreiben Teile ihrer Infrastruktur auf FreeBSD. OpenBSD wird eher für sicherheitskritische Front‑Ends eingesetzt, wo die Angriffsfläche minimal sein soll – beispielsweise als Reverse‑Proxy mit pf und httpd.
NetBSD wird selten in klassischen Web‑Umgebungen eingesetzt, findet aber in Embedded‑Gateways (Router, IoT‑Edge‑Devices) Verwendung, weil es auf ARM‑ und MIPS‑Boards läuft. DragonFlyBSD ist besonders attraktiv für Rechenzentren, die hohe Kernzahlen nutzen – das HAMMER2‑Dateisystem bietet native Deduplizierung, was Speicher‑Kosten senkt.
Firewall‑ und Router‑Appliance
pf wurde ursprünglich von OpenBSD entwickelt und später nach FreeBSD portiert. Heute ist pfSense (FreeBSD) und OPNsense (FreeBSD) die führenden Open‑Source‑Firewalls – sie bauen auf pf auf, bieten eine Web‑UI, Plugins für VPN, Captive‑Portal und IDS/IPS. OpenBSD selbst kann dank pf und spamd ebenfalls als reine Firewall dienen, wird aber seltener als eigenständige Appliance eingesetzt, weil es kein integriertes Web‑Frontend hat.
Embedded / IoT
NetBSD ist das klar dominante BSD‑Projekt für Embedded‑Systeme: Es läuft auf Raspberry Pi, BeagleBoard, MIPS‑Router, PowerPC‑Systemen und sogar auf Spielkonsolen. Die Clean‑room‑Entwicklung sorgt für stabile, deterministische Builds, die in der Industrie geschätzt werden. FreeBSD hat ebenfalls ARM‑Support, aber das Footprint ist größer, weshalb es primär in NAS‑Geräten (z. B. TrueNAS) verwendet wird.
Desktop / Workstation
FreeBSD selbst ist nicht primär für Desktop‑Nutzer gedacht, aber Projekte wie GhostBSD und MidnightBSD bieten fertig vorkonfigurierte Desktop‑Umgebungen (GNOME/KDE) mit ein‑Klick‑Installern. NetBSDs NomadBSD ist ein Live‑USB‑System, das persistent bleiben kann. DragonFlyBSD nutzt ebenfalls einen Desktop‑Installer, ist aber stärker auf Server‑Anwendungen ausgerichtet.
Storage‑Appliances und NAS
ZFS‑Integration macht FreeBSD zum bevorzugten Kernel für TrueNAS CORE (ehemals FreeNAS). Dort werden Snapshots, Replikation und RAID‑Z professionell verwaltet. DragonFlyBSD bietet HAMMER2, das ebenfalls Copy‑on‑Write, Snapshots und Deduplizierung unterstützt – ideal für Backup‑Server, die große Datenmengen deduplizieren wollen.
Kernarchitektur im Detail
Dateisysteme und Speicherverwaltung
FreeBSD – ZFS
ZFS ist ein Copy‑on‑Write‑Dateisystem, das Datenintegrität durch Checksummen gewährleistet. Es unterstützt Kompression, Deduplizierung, scrubbing und end‑to‑end‑Encryption. In FreeBSD ist ZFS seit Version 9.0 integral und kann als Root‑Dateisystem verwendet werden. Das Zpool‑Modell erlaubt das Kombinieren unterschiedlicher physischer Laufwerke zu einem logischen Speicher‑Pool.
Lizenz: ZFS stammt aus dem CDDL‑Open‑Source‑Projekt von Sun/Oracle, das mit der BSD‑Lizenz nicht kompatibel ist – deshalb existiert eine separate Lizenz‑Ausnahme in FreeBSD.
OpenBSD – FFS + Soft‑crypto
Das Fast File System (FFS), auch als UFS bekannt, ist das traditionelle BSD‑Dateisystem. OpenBSD hat keine native ZFS‑Unterstützung, jedoch gibt es experimentelle Ports. Für Verschlüsselung nutzt OpenBSD soft‑crypto, ein Kernel‑Framework, das Block‑Device‑Verschlüsselung auf Ebene des Dateisystems ermöglicht (z. B. bioctl -c C für GELI‑Verschlüsselung).
NetBSD – WAPBL und FFS
NetBSD verwendet ebenfalls FFS. Das WAPBL (Write‑Ahead‑Physical‑Logging) ist ein leichtgewichtiges Journal, das nur Metadaten‑Updates protokolliert, wodurch ein gutes Gleichgewicht zwischen Performance und Datenintegrität entsteht.
DragonFlyBSD – HAMMER2
HAMMER2 ist ein eigens entwickeltes Dateisystem, das Copy‑on‑Write, Snapshots, Deduplizierung und Cluster‑Level‑Mirroring (via hammer2 cluster) unterstützt. Es ist hoch skalierbar und besonders gut für Systeme mit vielen CPU‑Kernen und großen Datenmengen geeignet. Im Vergleich zu ZFS fehlt jedoch die breite Dritt‑Tool‑Unterstützung (z. B. zpool‑Utility).
Netzwerk‑Stack und Sicherheitsfeatures
FreeBSD: Der Netzwerk‑Stack ist für hohe Durchsatzraten optimiert (TCP‑Fast‑Open, RACK‑Congestion‑Control). ipfw ist das traditionelle Firewall‑Framework, aber seit FreeBSD 12 gibt es auch pf, das aus OpenBSD stammt. Das bpf-Subsystem (Berkeley Packet Filter) ermöglicht sehr effizientes Packet‑Capturing, das in Intrusion‑Detection‑Systemen genutzt wird.
OpenBSD: Der pf‑Firewall‑Engine ist das Herzstück. OpenBSD legt extremen Wert auf Code‑Reviews, Memory‑Safety (z. B. ProPolice, Stack‑Canaries) und Standard‑Hardenings (z. B. sysctl‑Defaults, disable_ipv6, login.conf). OpenBSD ist das Referenzsystem für PF, OpenSSH und LibreSSL, die in vielen anderen Projekten wiederverwendet werden.
NetBSD: Unterstützt sowohl ipfilter, ipfw als auch pf (via Port). Der Netzwerk‑Stack ist sehr portabel – das macht NetBSD attraktiv für kleine Router‑Boards.
DragonFlyBSD: Hat ebenfalls pf integriert, nutzt aber zusätzlich das Vimage/-Vkernel‑Framework für leichte Isolation von Netzwerk‑Namespaces. Der Netzwerk‑Stack ist nicht ganz so umfangreich wie bei FreeBSD, dafür aber sehr sauber implementiert.
Virtualisierung, Container und Isolationstechniken
System
Container‑Lösung
Hypervisor
Besonderheiten
FreeBSD
Jails – OS‑Level‑Container mit eigenen IP‑Stacks, Dateisystem‑Views und Ressourcengrenzen (via rctl).
bhyve – moderner Hypervisor, unterstützt VirtIO‑Devices, UEFI‑Boot und KVM‑Kompatibilität.
runjail ermöglicht Docker‑Kompatibilität; vmm-Modul für KVM‑Beschleunigung.
Fokus liegt auf Sicherheit, daher kein Container‑Framework eingebaut.
NetBSD
Keines (kein jails‑Äquivalent)
Xen, bhyve, hyper‑v (via hv‑Modul).
Sehr breite Unterstützung, jedoch weniger gebündelte Tools.
DragonFlyBSD
Vkernel – leichtgewichtige, eigenständige Kernel‑Instanz für Isolation (ähnlich zu jails aber mit weniger Overhead).
–
Vkernel ist ideal für Micro‑VMs und Container‑ähnliche Workloads.
Durch die Kombination aus Jails (FreeBSD) und pf (OpenBSD) können Administratoren sehr feinkörnige Sicherheits‑ und Isolation‑Modelle bauen, die sowohl Performance als auch Härtung liefern.
Moderne Angular‑UI, IDS/IPS (Suricata), Let’s Encrypt‑Integration, regelmäßige Security‑Updates.
NomadBSD
NetBSD
Live‑USB + Persistent Storage
Einfaches Live‑System, persistente Änderungen, kleine Image‑Größe.
OpenBSD‑based Tools
OpenBSD
Sicherheitstools
OpenSSH, OpenBGPD, OpenNTPD, LibreSSL, häufig in anderen Distributionen eingebettet.
DragonFlyBSD‑Bob
DragonFlyBSD
Server‑Skalierung
Minimalistisches System, fokussiert auf HAMMER2‑Performance, geringer Overhead.
Durch das breite Derivat‑Ökosystem kann ein Unternehmen das für den jeweiligen Anwendungsfall passende Betriebssystem wählen, ohne tief in die Grund‑BSD‑Distribution einsteigen zu müssen.
Pro‑ und Contra‑Tabellen – Schnellvergleich
FreeBSD
Pro
Contra
Riesige Ports‑Datenbank (≈30 k Pakete)
Größerer Footprint – weniger geeignet für ressourcenarme Embedded‑Geräte
Portabilität, pkgsrc für plattformübergreifende Pakete
Berücksichtigen Sie zusätzlich Community‑Aktivität, Verfügbarkeit von Paketen (Ports vs. pkg), Lizenz‑Konformität und Unterstützungsoptionen (Mailing‑Liste, Issue‑Tracker, kommerzielle Anbieter).
Zukünftige Entwicklungen und Roadmaps
FreeBSD 15.x – Weiterentwicklung des ZFS‑Stacks (z. B. ZFS 2.2 mit Verbesserungen bei Scrubbing und Compression), Unterstützung von GPU‑Pass‑Through für bhyve, engere Integration in Kubernetes via csi‑freebsd.
OpenBSD 7.9 – Verbesserungen am pf‑Engine (z. B. stateful‑inspection Optimierungen), Einführung von Trusted Execution Environments (TEE), erweiterte Hardware‑Root‑of‑Trust‑Mechanismen.
NetBSD 10 – Fokus auf RISC‑V‑Unterstützung (neue Toolchains, Device‑Tree‑Support), pkgsrc‑Erweiterungen für Container‑Orchestrierung (Docker‑Kompatibilität), Modernisierung der Netz‑Stack‑Bibliotheken.
DragonFlyBSD 6 – Finalisierung und Stabilisierung von HAMMER2, neue Vkernel‑Features (z. B. Namespace‑Isolation, cgroups‑ähnliche Ressourcen‑Limits), Integration von ZFS‑Ports für Hybrid‑Lösungen.
Derivate: TrueNAS SCALE (Debian‑basiert) entsteht als Konkurrenz zum FreeBSD‑basierten CORE, während pfSense 2.8 führt eBPF‑Unterstützung ein, um modernere Packet‑Processing‑Pipelines zu ermöglichen.
Quellen, weiterführende Literatur und Community‑Links
In unserem ausführlichen Erfahrungsbericht schildern wir, wie unser autistischer Sohn nach einem vielversprechenden Start am Internat Alzen wiederholt von Mitschülern belastet wurde und wir dies frühzeitig dokumentiert und gemeldet haben. Aus unserer Sicht reagierte die Schule nicht mit ausreichenden Schutzmaßnahmen, sondern hielt an einem festen Konzept fest, das die Situation unseres Kindes nicht angemessen berücksichtigte. Wenige Wochen nach unseren Hinweisen auf die Problematik wurde das Schulverhältnis beendet.
Wir ordnen den Fall im Kontext von Kinderschutz, Inklusion und schulischer Verantwortung ein und geben Hinweise, worauf Eltern in ähnlichen Situationen achten sollten und berichten von unseren Erfahrungen.
Ich, der derzeit fast ausschließlich seit sechs Jahren MacBooks nutzt und relativ glücklich mit seinem M5-Gerät ist, wollte schon immer mal FreeBSD auf einem Notebook ausprobieren. Ein gut kompatibles Gerät hatte ich bisher nie finden können, doch tauchte dann irgendwann ein Artikel auf, der meinte, dass das Lenovo T480 gut mit FreeBSD funktioniert. Also habe ich mir eins bei eBay für 170 Euro geklickt. 14″, i5, 256GB SSD, 16GB RAM. Nichts tolles, aber zum herumspielen reicht es, dachte ich.
Ich habe eine kurze Weile OpenBSD auf einem Eee-PC vor vielen Jahren genutzt und das Ding sogar mal für eine Weile mit ins Krankenhaus genommen. Es funktionierte echt gut, sogar Suspend und Resume. Leider ging es dann kaputt.
Das Gerät kam an, Windows 11 war installiert. Ich habe es direkt platt gemacht und FreeBSD 15 amd64 von einem USB-Stick installiert. Letztlich eine Standardinstallation. Was funktioniert alles?
Grafikkarte funktioniert, Monitor wird mit voller Auflösung (naja, ist nur Full-HD) unterstützt
Tastatur geht
Trackpad geht, auch mit Scrolling
Trackpoint geht auch
Der SD-Card-Reader funktioniert
WLAN- und Ethernet funktionieren
Beide Akkus (interner und externer) werden erkannt
Tonausgabe geht
USB-Anschlüsse funktionieren
Suspend und Resume funktionieren
Bluetooth
Was ich noch nicht ausprobiert habe, sind:
Smart-Card-Reader
HDMI-Anschluss
Installiert habe ich Xorg, KDE und ein wenig Software. Das Gerät funktioniert recht gut und für jemanden, der unbedingt FreeBSD auf einem Notebook haben möchte, ist es nicht schlecht, wenn man denn mit den ganzen Nachteilen leben kann (langsamer Prozessor, schlechte Grafikkarte, schlechter Bildschirm, mittelmäßiges Trackpad, billiges Plastikgehäuse).
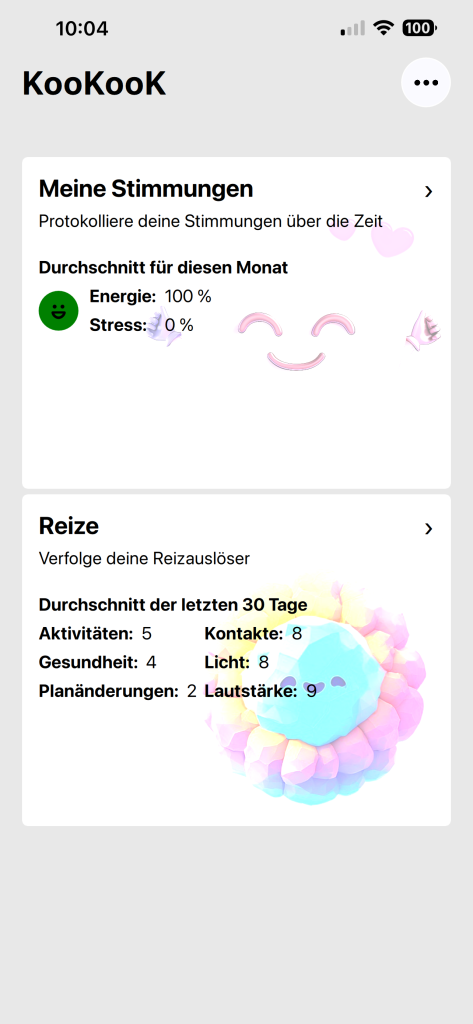
Vor einiger Zeit wollte ich mich mit QML näher auseinandersetzen und suchte nach einer Projektidee. Als Domain hatte ich noch „kookook.org“ bei mir registriert und dachte, dass ich einfach damit was mache. Bei der Projektidee ging es, allen voran, darum, dass ich mich mit dieser Technik auseinandersetzen und mich vor allem auf mobile Plattformen (iOS, Android) konzentrieren wollte.
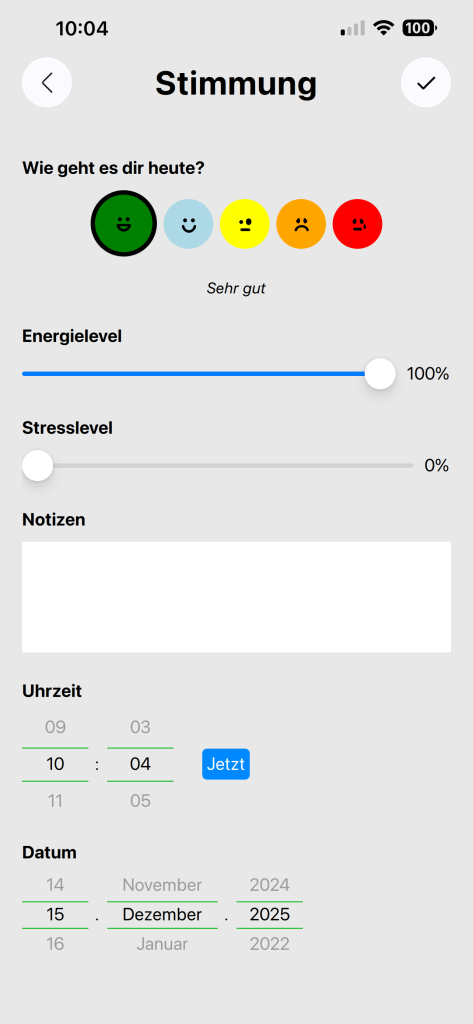
Ich habe mich entschieden, an einer App für neurodivergente Menschen zu arbeiten, um ein Ziel vor Augen zu haben. Herausgekommen ist jetzt eine kleine App, mit der man seine Stimmungen und Reize tracken kann. Das Programm kann noch nicht viel, aber vielleicht interessiert es jemanden.
Es gibt auch eine Android-Version, die ist im Google Play Store allerdings noch nicht freigegeben, da ich dafür erst 12 Tester benötige und mir dazu gerade die Zeit fehlt. Wer Lust hat: Gerne per E-Mail an mich, ich schalte die Version dann frei.
Die App ist kostenlos und benötigt keine Internetverbindung.
Ich werde immer wieder gefragt, was ich eigentlich genau mache. Die kurze Antwort: Ich entwickle Software und administriere Systeme, vornehmlich unter FreeBSD. Die längere Antwort ist dieser Beitrag.
Meine Arbeit bewegt sich im Spannungsfeld zwischen Softwareentwicklung, Infrastruktur und Systemarchitektur. Ich helfe dabei, Systeme zu bauen oder zu stabilisieren, die langfristig funktionieren – technisch sauber, verständlich und wartbar.
Softwareentwicklung: Qualität statt Fließband
In meinen Blog-Artikeln über Softwareentwicklung habe ich viel darüber geschrieben, was in Unternehmen schief läuft: unlesbarer Code, fehlende Architektur, technische Schulden, die niemand mehr anfasst, und ein Fokus auf Prozesse statt auf das Produkt selbst. Das ist keine abstrakte Kritik, sondern Dinge, die ich über viele Jahre hinweg in verschiedenen Unternehmen hautnah erlebt habe.
Daraus folgt, was ich anbiete: saubere, lesbare, wartbare Software. Code, den auch jemand anderes in fünf Jahren noch versteht. Ich habe langjährige Erfahrung in verschiedenen Programmiersprachen – von der systemnahen Programmierung bis hin zu komplexen GUI-Anwendungen mit Qt und wxWidgets. Datenbanken (insbesondere PostgreSQL) gehören ebenso dazu wie Server-Client-Architekturen und Netzwerkprogrammierung.
Wenn du ein Projekt hast, das aus dem Ruder gelaufen ist, das von einer Einzelperson entwickelt wurde und jetzt kaum noch jemand durchblickt, oder das dringend eine saubere Neuarchitektur braucht – dann bin ich die richtige Ansprechperson.
FreeBSD begleitet mich seit Version 4, also seit über zwei Jahrzehnten. Ich betreibe eigene Server damit, kenne ZFS mit RAIDz, FreeBSD-Jails, Bhyve, pf, CARP, HAST und die gängigen Netzwerkdienste (DNS, DHCP, NTP, NFS, Samba, LDAP u.v.m.) aus der täglichen Praxis – nicht nur aus der Dokumentation.
Was ich löse: Du brauchst einen stabilen, sicheren Server oder eine skalierbare Serverinfrastruktur unter FreeBSD? Du möchtest Dienste in Jails isolieren? Du hast ein laufendes System, das Pflege oder Erweiterung braucht? Oder du stehst vor einem konkreten Problem, das sich partout nicht lösen lässt? Ich bin mit solchen Situationen vertraut – und finde pragmatische Lösungen.
Für Unternehmen
Falls du als Unternehmen schaust: Ich bringe Softwareentwicklung und Systemadministration zusammen. Ich bin kein Spezialist, der nur eine Schraube dreht, sondern jemand, der Systeme im Ganzen versteht. Ich habe in Firmen gearbeitet, in denen beides gefragt war, und weiß, wie wichtig es ist, dass Entwicklung und Infrastruktur zusammenpassen.
Ich schätze eine Unternehmenskultur, in der Fehler als Lernmöglichkeit begriffen werden, Kompetenzen sinnvoll eingesetzt werden und das Produkt im Mittelpunkt steht – nicht das Verwalten von Tickets. Wenn das auch dein Ansatz ist, sollten wir sprechen (E-Mail: thorsten@tgeppert.de).
Vielleicht hilft das dem ein oder anderen. Ich habe 2023 gebraucht ein MacBook Pro 16″ (BJ 2019) als Zweitgerät auf Kleinanzeigen gekauft. Zwei Jahre lang hatte ich das in Benutzung, jetzt übergab ich es, aufgrund eines neuen Hardwarekaufs, an meinen Sohn. Also Programme, die er nicht braucht, gelöscht, Account angelegt und meinen Account gelöscht. So weit, so gut. Er hatte das Gerät jetzt gut eine Woche in Benutzung und forderte mich gestern, am 13.11.2025 auf, ihm nochmal das WLAN-Passwort zu geben, denn sein Mac sei irgendwie abgestürzt.
Ich sah mir das Gerät direkt einmal an und er hatte recht: Es versuchte, in den Internet-Recovery-Modus zu booten. Mir fiel dann ein, dass beim Erstellen vom Account meines Sohns irgendeine Apple-ID angezeigt wurde, die vom Vorbesitzer war. Anscheinend ist dieser informiert worden, dass da an seinem alten Mac gearbeitet wird. Er hat dann – so wie es aussieht – den Mac aus der Ferne vollständig gelöscht.
Zusätzlich bin ich nicht mehr in der Lage, den Mac überhaupt noch zu nutzen, da dieser via Apple-ID des Vorbesitzers entsperrt werden muss. Ich habe ihm einen Brief geschrieben (ich habe nur noch die Adresse und hoffe, er wohnt da noch) und darum gebeten, den Mac aus seinem Account zu entfernen. Wenn er das nicht macht, habe ich nur rechtliche Möglichkeiten, das zu verlangen, die aber wiederrum mit Aufwand und ggf. Kosten einhergehen. Ansonsten ist das Gerät nicht mehr als ein teurer Briefbeschwerer.
Mein Sohn ist natürlich enttäuscht und traurig. Ich hoffe, dass der Vorbesitzer noch einlenkt und alles wieder gut wird.
Also: Denkt beim Verkauf von Apple-Geräten daran, sie aus euren Accounts freizugeben und wenn ihr solche Geräte kauft, checkt das vorher. Ich denke nicht, dass hier böse Absicht hinter gesteckt hat, weiß es aber nicht. Natürlich sind alle Daten, Programme, usw. unwiderruflich gelöscht. Wohl dem, der ein Backup hat.
Als ich bei der Pleodat GmbH war, sollten sich mein neuer Kollege und ich vorstellen. Ich habe gerade die Präsentation gefunden und möchte sie hier veröffentlichen.